Puyo Puyo is a versus puzzle game with a rich competitive history spanning over 25 years, but is little known outside of Japan outside of the reskin Dr Robotnik's Mean Bean Machine or "that other game in Puyo Puyo Tetris". The purpose of this post is to lift the veil and help new players understand what's going through skilled Puyo players' minds during a match. It introduces the basic strategy of Puyo Puyo, breaks down the flow of a match, and explains some common vocabulary.
The Fundamentals
Four core mechanics have influenced the development of competitive Puyo Puyo:
Chains
Gameplay consists of players placing pieces of puyos upon the puzzle playfield in real time. When four or more puyos of the same color connect, they pop and disappear, and any uncleared puyos above fall down.
If those falling puyos then connect with additional groups of four same-colored puyos, they start a chain. This process continues until no more puyos can be matched.
The first puyos that start the chain are known as the trigger. Identifying the triggers (some chains may have more than one) is a key skill for Puyo mastery.
Garbage
Attacking in Puyo occurs by clearing chains to launch garbage at the other player. Garbage puyos fall from the top of the board and can only be erased by clearing adjacent puyos, making taking damage punishing while still offering a chance of recovery.
The amount of garbage an attack sends increases dramatically with chain length. Eating a 3 chain is enough to paralyze most boards, while an unanswered 5 chain will likely end the game single-handedly. While the theoretical maximum chain on a standard Puyo board is 19, live games seldomly produce anything longer than a 15 chain.
The garbage table for the first few chains. A 6 chain already sends enough garbage to fill up an entire board twicefold.
Countering
The counter mechanic allows players to defend against an incoming attack by setting off a chain of their own. The waiting garbage is reduced at a 1:1 rate, and if the defending chain is even more powerful, the overflow garbage will counterattack and be sent to the opponent's field instead.
Timing
If chaining and garbage can be thought of as resources, time can be thought of as the regulator of these resources. Not only do bigger chains take more time to build, they also take more time to pop. To make matters more complicated, a player who sets off a chain cannot place any additional pieces onto their board until their chain finishes clearing, while their opponent is free to continue building to set up a counterattack. One common line of play is to set off a small chain while still having another, bigger chain waiting. If the opponent tanks the garbage, follow up with the remainder of the chain to finish them off, but if they instead try to counter with everything, continue adding more puyos to the backup chain while the opponent is stuck watching the chaining animation, then crush them with a huge second chain.
The Game Plan
Broadly speaking, a Puyo match can be described as a race to see which player can build their ultimate chain first. A killer chain will knock out or cripple the opponent while overpowering any potential counterattacks.
Interaction with the opponent is a key component of Puyo Puyo. Both players are trying to reach the same goal, after all, and stopping the opponent's ultimate chain from being built is just as effective a strategy. Identifying flaws in the opponent's board state and disrupting their build with a sneak attack can have game-changing consequences. Of course, the opponent is trying to do the same thing, and careless play can be disastrous for the aggressor.
"Will this blitz open up the enemy to further strikes, or is their board hardended enough that I'd just be exhausting my own resources to fight off a later assault?" Puyo Puyo demands that questions like this be asked constantly, and it is this dynamic nature that makes Puyo such a exciting game to play and watch.
Parts of a chain
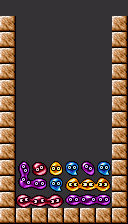
Puyo boards can look complex, but knowing how each piece contributes to the overall Game Plan simplifies the playing field tremendously. In this section, we'll be going over how to recognize the different parts of a chain as well as how each of the pieces of the puzzle fits in to the larger picture. Don't be worried if the first few matches you watch seem impenetrable initially - you'll get the hang of it over time.
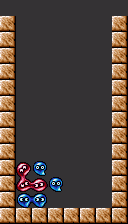
We'll be breaking apart this particular board as an example. The trigger puyos for the main chain are the yellows in column 3.
The yellow key puyo cannot be placed in column 2. Can you figure out why?
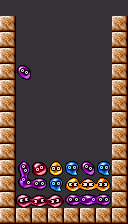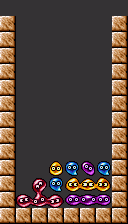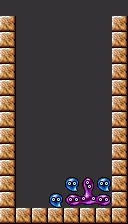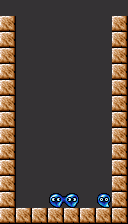
The Base
Just as the foundation of a mansion supports the massive building above it, the base of a Puyo chain provides a rock solid floor for the rest of the stack. As it dictates what kinds of chains can be built on top, the base is typically the first part of the chain to be completed.
A player who sets off the puyos in the base is either confident that the opponent is unable to profitably respond to an attack, or desperate for a last chance to keep themselves in the fight.
The Transition
Transitions guide the chain from the base to higher rows on the board. Due to the precise puyo requirements to build one, it is one of the most vulnerable parts of a chain, and opponents will often try to attack the transition before it is complete.
The Extension and Tail
Two sides of the same coin, extending and tailing refer to building out the "front" and "back" of the chain, respectively. The added links can add critical extra power to a chain.
Poorly built extensions and tails can make it difficult to lay down additional pieces on the board, separate from the rest of the chain, or accidentally set off portions of the main chain earlier than designed.
Pressure
Unlike the other sections, pressure is not intended to connect with the main chain, or even necessarily kill the opponent. Instead, it is designed to break apart the opponent's ultimate chain, limit their chaining potential, or seal away access to their resources. Efficient pressure recycles unwanted puyos and pops cleanly without compromising the integrity of the rest of the board. Even the threat of pressure may be enough to condition the opponent into making mistakes.
Putting it all together
Puyos aren't permanently locked into a role after they're placed on the board. Good players will try to find ways to repurpose puyos as the situation demands. For example, if the opponent is getting ready to launch a chain that requires full power as a response, the puyos originally intended as pressure can instead be fused into the main chain as an extension by placing just a few extra puyos!
An Example Match
Try and see if you can use what you've learned to identify what each player is trying to build. If you get lost, asides from how close to death each board is, you can use the score below each field as a rough estimate of total chaining power over the course of the game.
Common Terminology
Much like other games with a devoted following, Puyo has developed a lexicon of jargon to describe certain situations and game mechanics. Here's some common terms you may encounter during analysis and commentary:
Stairs
A chain pattern that resembles a staircase.
Sandwich
A chain pattern that resembles a sandwich. Has two variations that can be mixed, making it a versatile form.
GTR
The eponymous "Great Tanaka Rensa" is a popular chaining form due to its flat upper surface for transitions and ease of build.
It resembles a foot inside of a shoe.
Power Chain
In addition to chain length, Puyo also provides bonuses for clearing multiple colors of puyos, multiple distinct groups of puyos, and more than four puyos within one chain link. These are collectively known as power chains, and tend to trade off garbage potential for speed.
Two common power chains have special nicknames: Thorn (power-1) and Hellfire (power-2).
Cutting
Cutting occur when a chain ends earlier than expected due to stray puyos. While cuts tend to be accidental, they are also often created intentionally to catch the opponent off guard.
An extension converted into pressure via cutting.
Digging
Digging refers to clearing layers of garbage away to access the delicious candy underneath.
Smart digging can completely eradicate damage taken from an attack.
Ghosting
The visible board measures 6 columns by 12 rows; however a hidden 13th "ghost" row exists as well. Puyos placed here will not connect with anything underneath until they fall back onto the regular playing field.
All clear
Clearing all puyos off the board grants the player a one-time all clear bonus, which adds 30 garbage (5 rows) to the next chain the player sends.
Counter (chain)
Garbage in Puyo falls in stacks of up to 30 at a time. Counter chains take advantage of this by building the trigger high enough that the chain can be accessed even after a round of garbage has covered the rest of the board. Counter builds are a popular defense mechanism against all clear boards.
Harassment
Another expression for offensive chaining pressure.
Turnaround
Another expression for a transition due to how it affects the direction the chain resolves in.
Margin Time
While Puyo has no round timer, it does have a sudden death mechanic to help draw games to a close. Starting at 96 seconds, the game will gradually increase the garbage multiplier that chains send.
Final Thoughts
Puyo Puyo is an oddball amongst other contemporary esports: the rules are relatively simple, there are no character tiers or differences between sides (in fact, both players get the exact same piece RNG), and the core game has changed very little in the decades since its initial release. Yet over the years, Puyo battles have cultivated a dedicated fanbase, inspired volumes of strategies, and incubated personalities so diverse some players can be identified solely by how they build their chains. I find these aspects to be a testament to how solid Puyo's fundamental mechanics are and a good sign that it is here to stay. I hope you'll get as much enjoyment out of Puyo Puyo as I have all these years.





























awesOme
unbeLievable